|
I am a Staff Research Scientist at Google DeepMind, where I lead research on GenRetrieval and Semantic IDs for personalization in Large Language Models. Recent talk: GenRetrieval Research - slides from my talk on generative retrieval for recommendations. I received my Ph.D. from Duke University, advised by Professor Lawrence Carin, with a thesis on Continual Learning of Deep Neural Networks. During my PhD, I interned at Meta FAIR, Google Brain, and Google AutoML. Prior to Duke, I was a research associate at IIT Kanpur, where I worked with Professor Piyush Rai and Professor Gaurav Pandey. Email / Google Scholar / Linkedin / Github |

|
|
My research focuses on Generative Retrieval, personalization with LLMs, and deep learning. For a complete list, see my Google Scholar. |
 |
Google DeepMind Technical Report, 2025 Research on video tokenization recipes for understanding and VQA tasks. Preparing and implementing evaluation benchmarks for VQA using YouTube videos. |
 |
R. He, L. Heldt, L. Hong, R. Keshavan, S. Mao, N. Mehta, Z. Su, A. Tsai, Y. Wang, et al. Technical Report, 2025 Adapting pre-trained language models for industrial-scale generative recommendations at Google. |
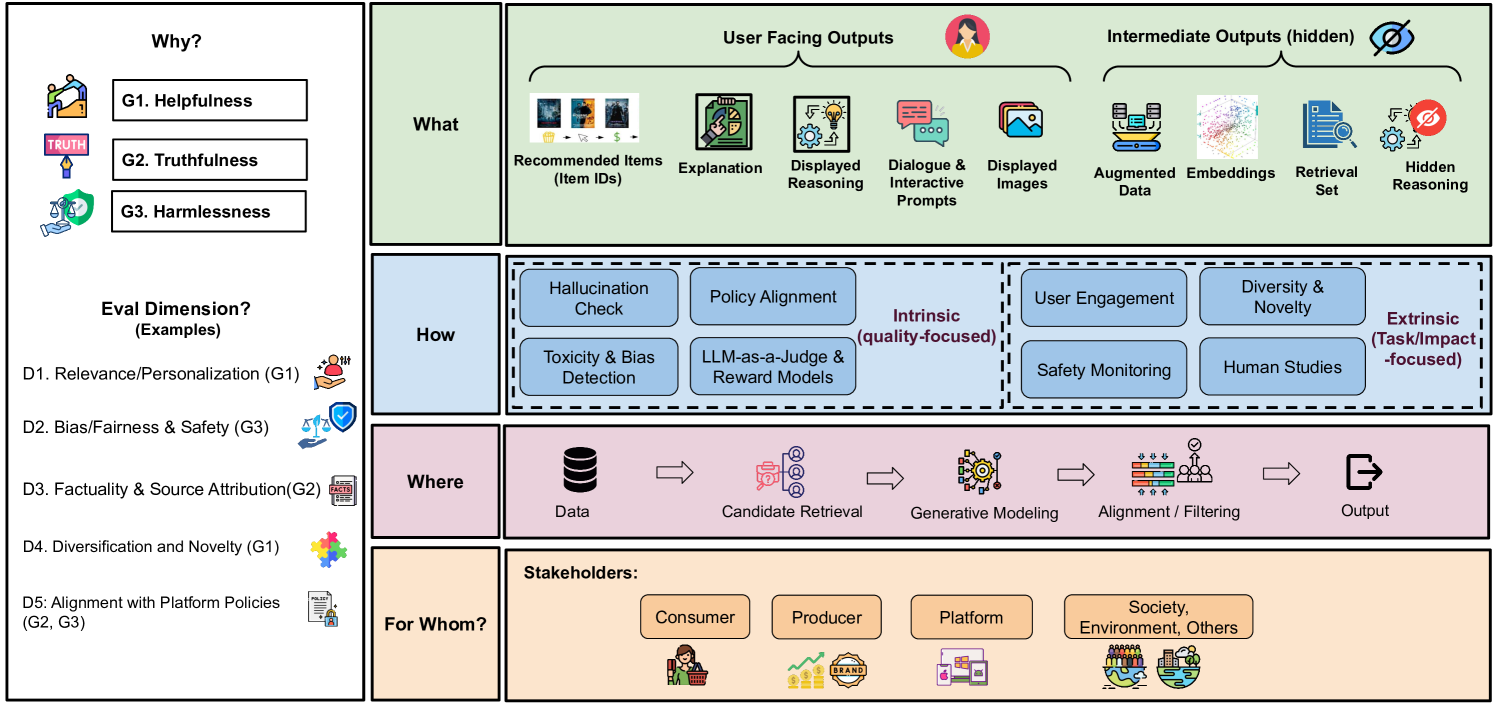 |
Y. Deldjoo, N. Mehta, M. Sathiamoorthy, S. Zhang, P. Castells, J. McAuley ACM SIGIR, 2025 A framework for holistic evaluation of recommender systems powered by generative models. |
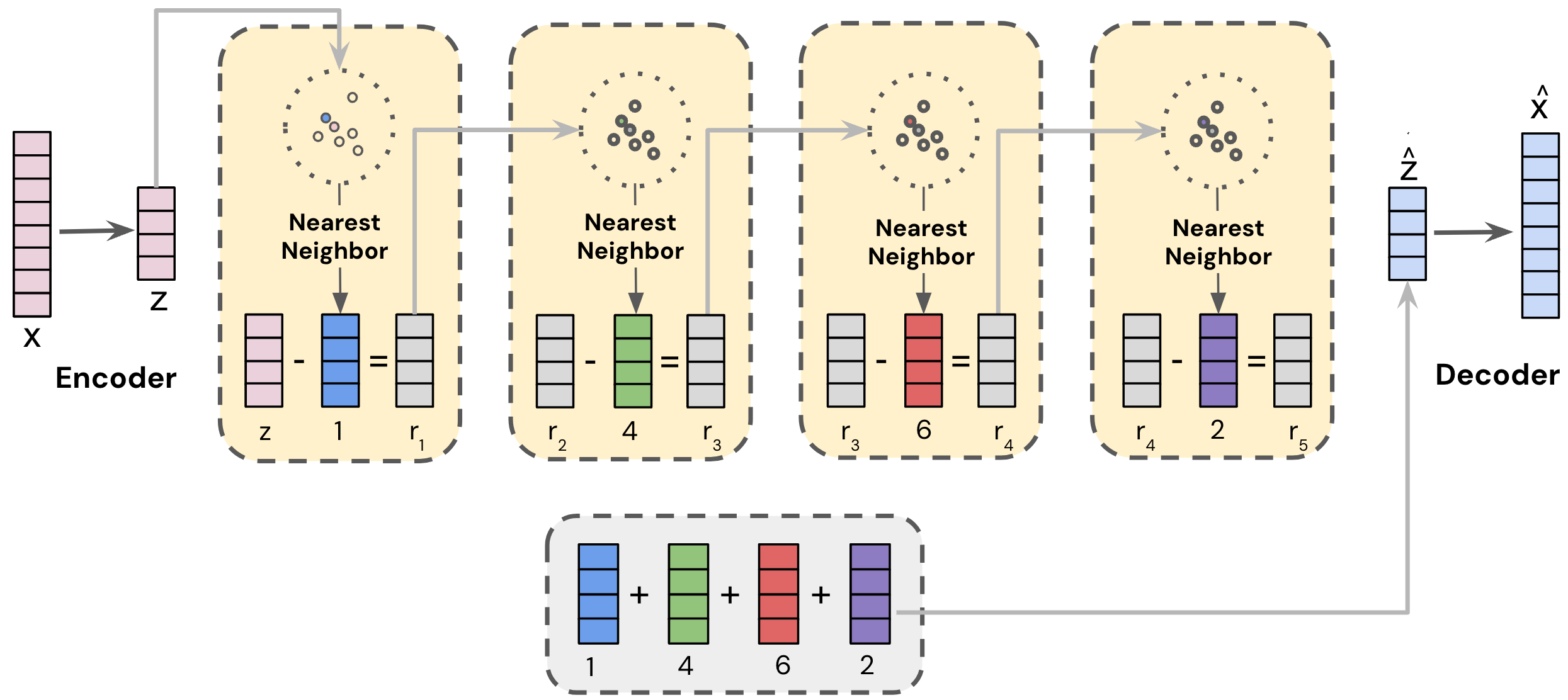 |
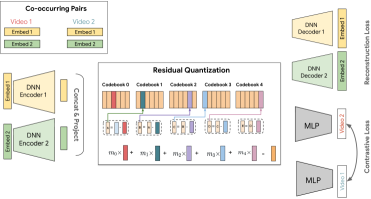
A. Singh*, T. Vu*, N. Mehta*, R. Keshavan, M. Sathiamoorthy, Y. Zheng, L. Hong, L. Heldt, L. Wei, D. Tandon, E. Chi & X. Yi ACM RecSys, 2024 (Runner-up Best Short Paper) Semantic IDs for representing items in corpus, enabling better generalization in ranking for recommendations. |
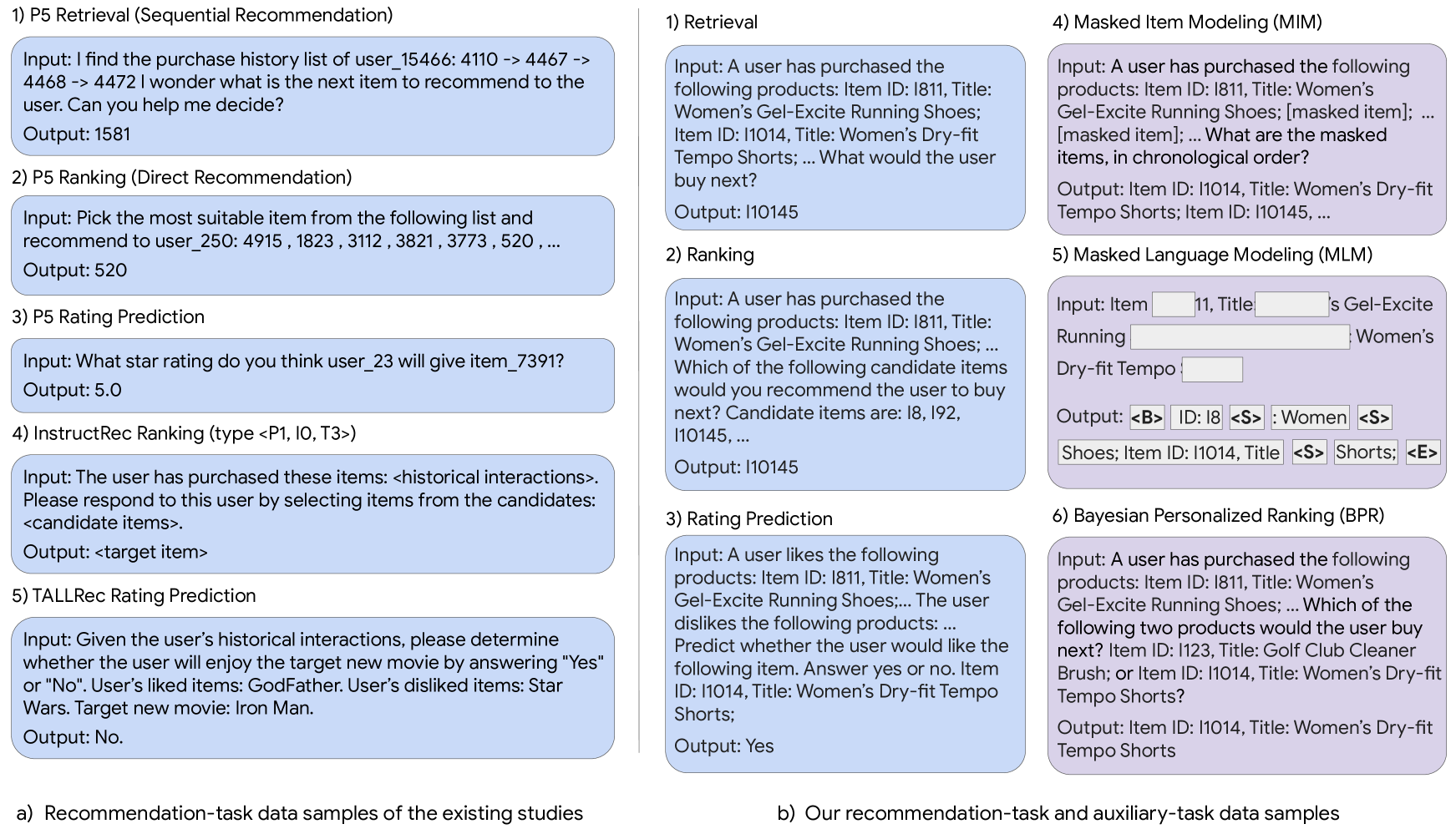 |
Y. Cao, N. Mehta, X. Yi, R. Keshavan, L. Heldt, L. Hong, E. Chi & M. Sathiamoorthy Findings of NAACL, 2024 Methods for aligning large language models with recommendation knowledge for improved personalization. |
 |
N. Mehta, K. Liang, J. Huang, F. Chu, L. Yin, & T. Hassner WACV, 2024 A novel method for out-of-distribution detection and classification in few-shot learning settings. |
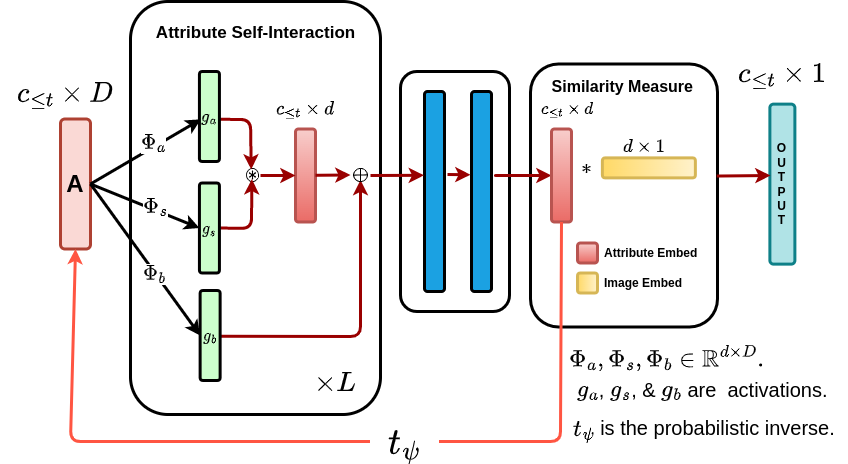 |
V. Verma*, N. Mehta*, K. Liang, & L. Carin WACV, 2024 A meta-learned approach for attribute self-interaction in continual and generalized zero-shot learning. |
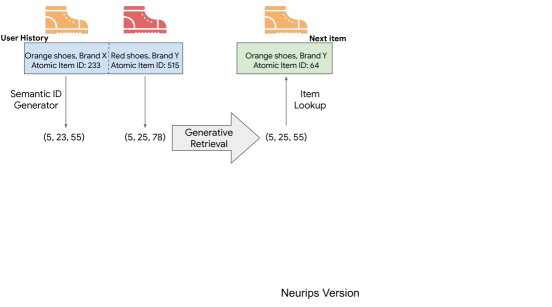 |
S. Rajput*, N. Mehta*, A. Singh, R. Keshavan, T. Vu, L. Heldt, L. Hong, Y. Tay, V. Tran, J. Samost, M. Kula, E. Chi & M. Sathiamoorthy NeurIPS, 2023 Invented GenRetrieval for recommendation systems, now adopted across multiple companies including Spotify, Meta, Snap, Amazon, Kuaishou, and Doordash. |
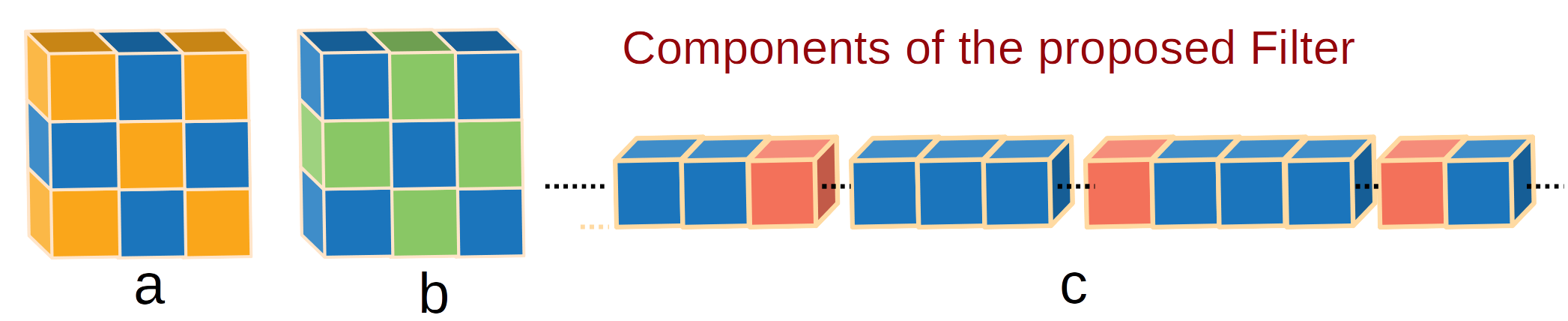 |
V. Verma*, N. Mehta*, S. Si & L. Carin WACV, 2023 Methods for pushing the efficiency limit of deep networks using structured sparse convolutions. |
 |
V. Verma, K. Liang, N. Mehta, P. Rai, & L. Carin CVPR, 2021 A task-specific feature map transformation strategy for continual learning, which adds minimal parameters to the base architecture while outerperformaing previous methods in discriminative and generative tasks. |
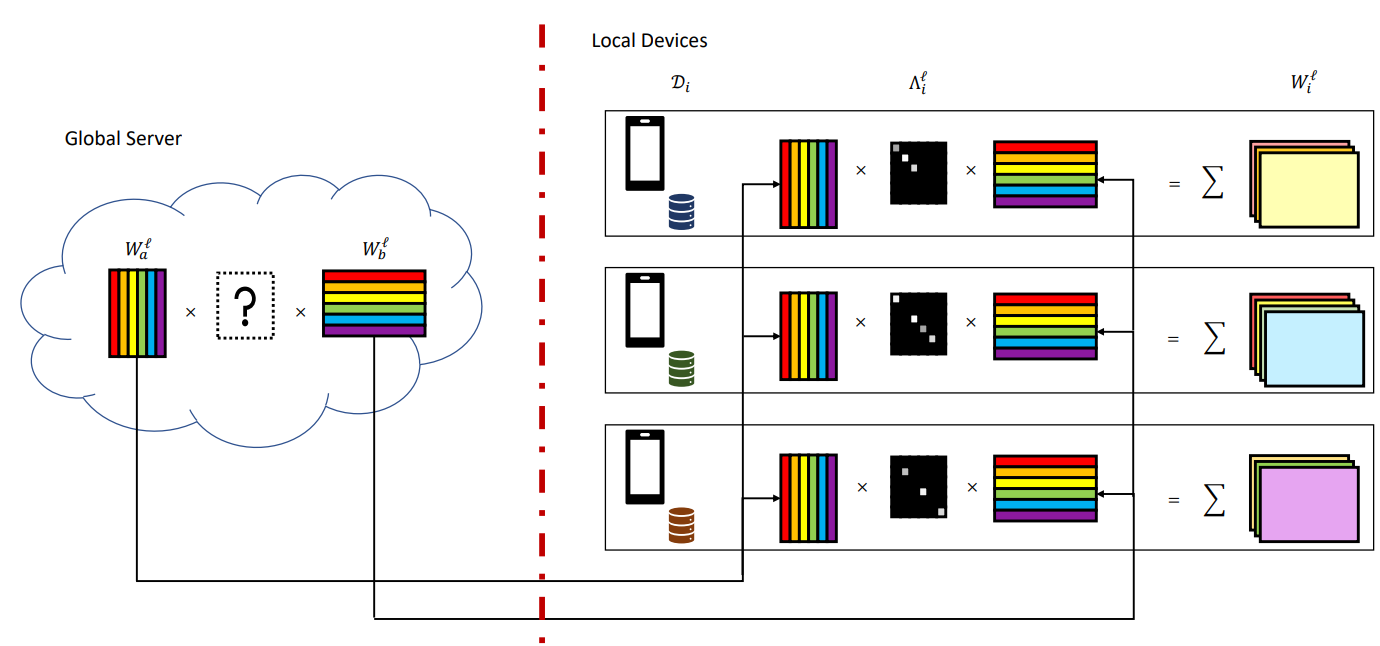 |
W. Hao, N. Mehta, K. Liang, P. Cheng, M. Khamy & L. Carin IEEE Access, Volume 10 A Bayesian nonparametric framework using shared rank-1 weight factors for federated learning. |
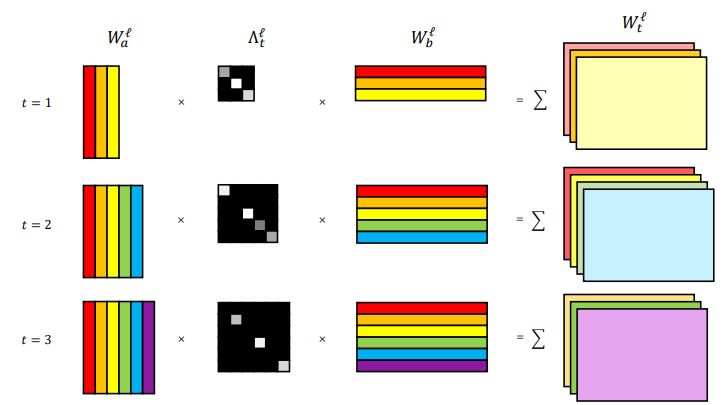 |
N. Mehta, K. Liang, V. Verma, & L. Carin AISTATS, 2021 Continual Learning using Bayesian Nonparametrics and layer-wise dictionary of weight factors. |
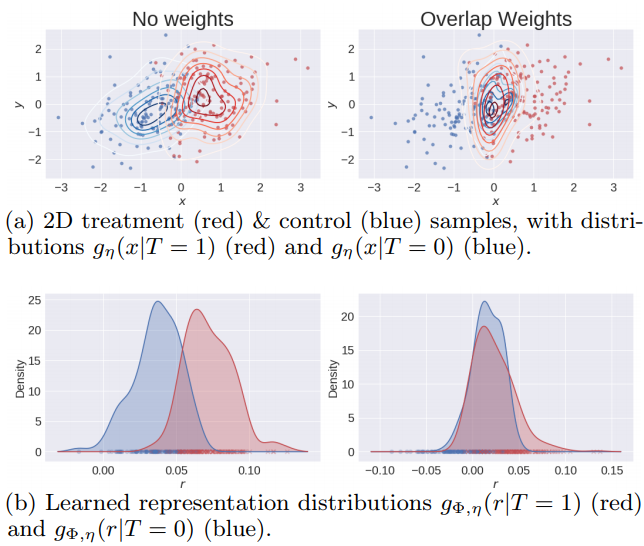 |
S. Assaad, S. Zeng, C. Tao, S. Datta, N. Mehta, R. Henao, F. Li, & L. Carin AISTATS, 2021 Counterfactual Representation Learning with Balancing Weights |
 |
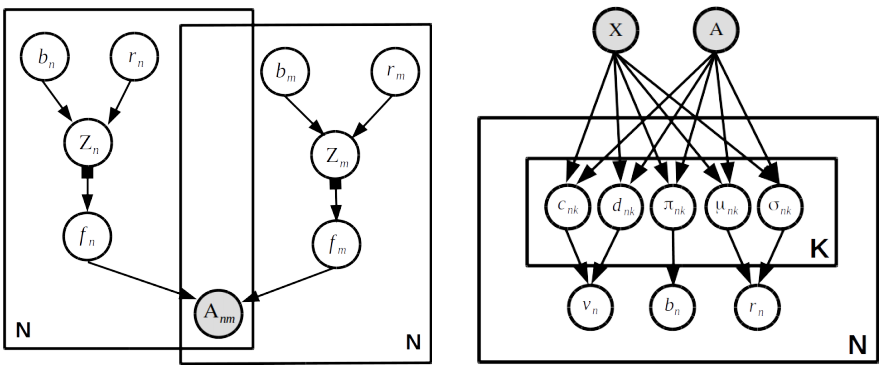
A. Sarkar*, N. Mehta*, & P. Rai AAAI, 2020. Early version appeared at Graph Representation Learning Workshop (NeurIPS). A Gamma Ladder Variational Autoencoder for graph-structured data that brings together the interpretability in hierarchical, multilayer latent variable models and the strong representational power of graph encoders. |
 |
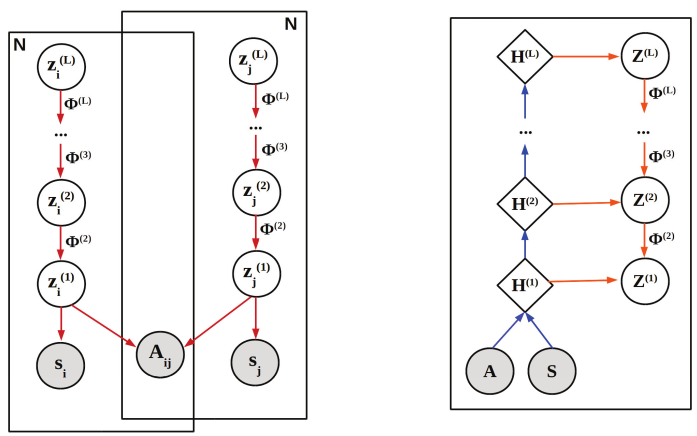
N. Mehta, L. Carin & P. Rai ICML, 2019 A deep generative framework for overlapping community discovery and link prediction combining the interpretability of stochastic blockmodels, such as the latent feature relational model, with the modeling power of deep generative models. |
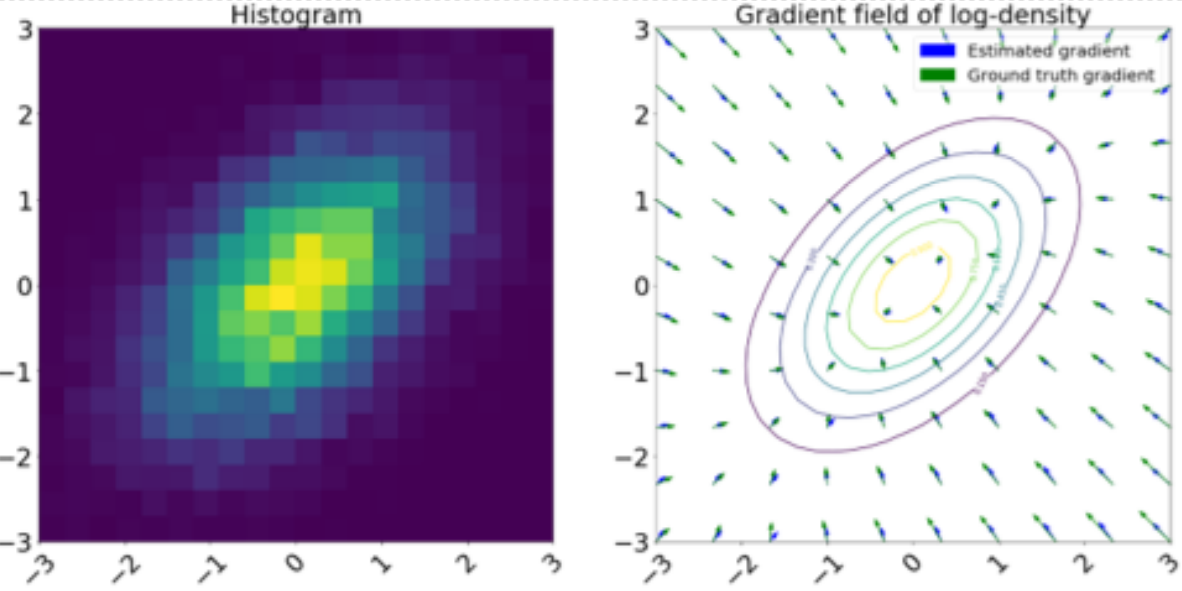 |
N. Mehta*, Jiachang Liu*, Chenyang Tao & L. Carin, Workshop on Stein’s Method. ICML, 2019 We propose using Stein's Method to estimate the parameters of a distribution based on given samples. We also estimate the score function of the empirical distribution and propose a new generative model combining Stein score matching with the Langevin flow. |
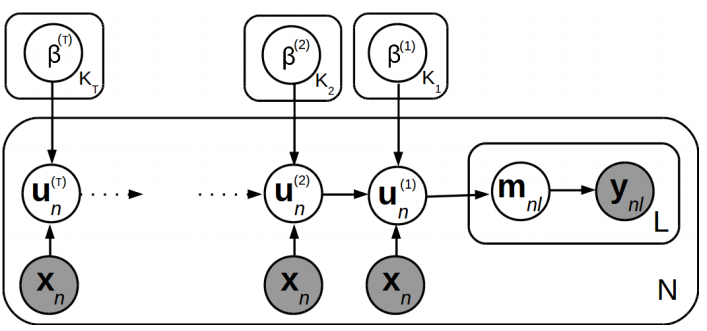 |
R. Panda, A. Pensia, N. Mehta, M.Zhou & P. Rai AISTATS, 2019 We present a probabilistic framework for multi-label learning based on a deep generative model for the binary label vector associated with each observation. |
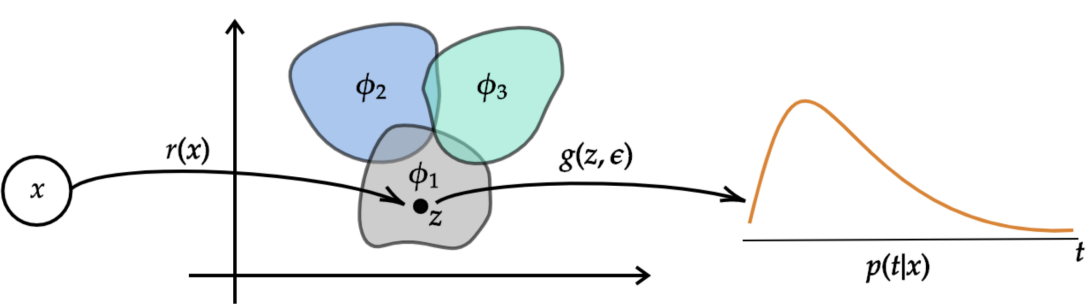 |
P. Chapfuwa, C. Li, N. Mehta, L. Carin and R. Henao CHIL, 2019 A Bayesian nonparametric model for jointly inferring the time-to-event and the individualized risk-based cluster assignments. |
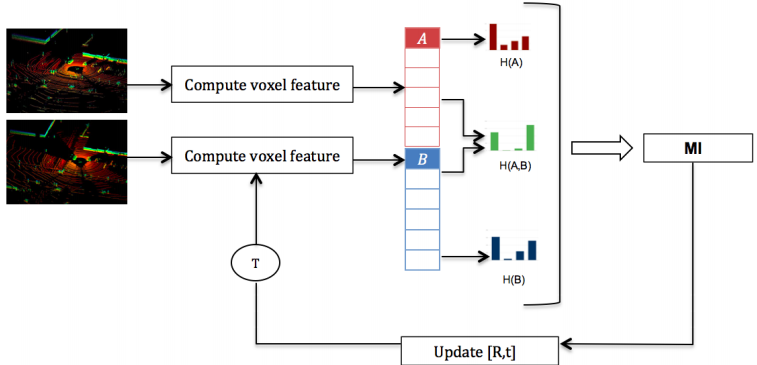 |
N. Mehta, J. McBride & G. Pandey ICRA, 2018 A mutual information based algorithm for the estimation of full 6-degree-of-freedom (DOF) rigid body transformation between two overlapping point clouds. |
|
Forked from Jon Barron's page. |